فایل robots.txt چیست؟ {چطور با robots.txt مسیر رباتهای گوگل رو کنترل کنیم؟ + نمونه فایل robots.txt}
در یکی از پروژهها، مقالات بهسختی ایندکس میشدن، انگار گوگل با سایت ما قهر کرده بود! بعداً فهمیدیم تنظیم اشتباه robots.txt باعث هدررفت بودجه خزش شده و در نهایت، پروژه سئو توسط کارفرما کنسل شد.
این تجربه تلخ یکی از مشتریان میزفا تولز، دلیل نوشتن این مقاله شد تا یاد بگیریم چگونه این فایل را درست تنظیم کنیم و از آسیب به کسبوکارها جلوگیری کنیم.
در این مقاله قراره به این بپردازیم که فایل robots.txt چطور کار میکنه و چرا استفاده از این فایل برای بهینهسازی سایت و جلوگیری از ایندکس شدن اطلاعات حساس اهمیت زیادی داره. همچنین، یکی از افزونههای کاربردی مثل میزفا تولز رو به شما معرفی میکنیم که به راحتی میتونید فایل robots.txt سایتتون رو مشاهده و مدیریت کنید، بدون اینکه نیاز به تخصص خاصی داشته باشید.

فايل robots.txt چيست؟
robots.txt يك فايل متنی سادست كه که به موتورهای جستجو میگه کدوم صفحات رو بخزن یا کراول (crawl) کنن و کدوم صفحات رو نادیده بگیرن.
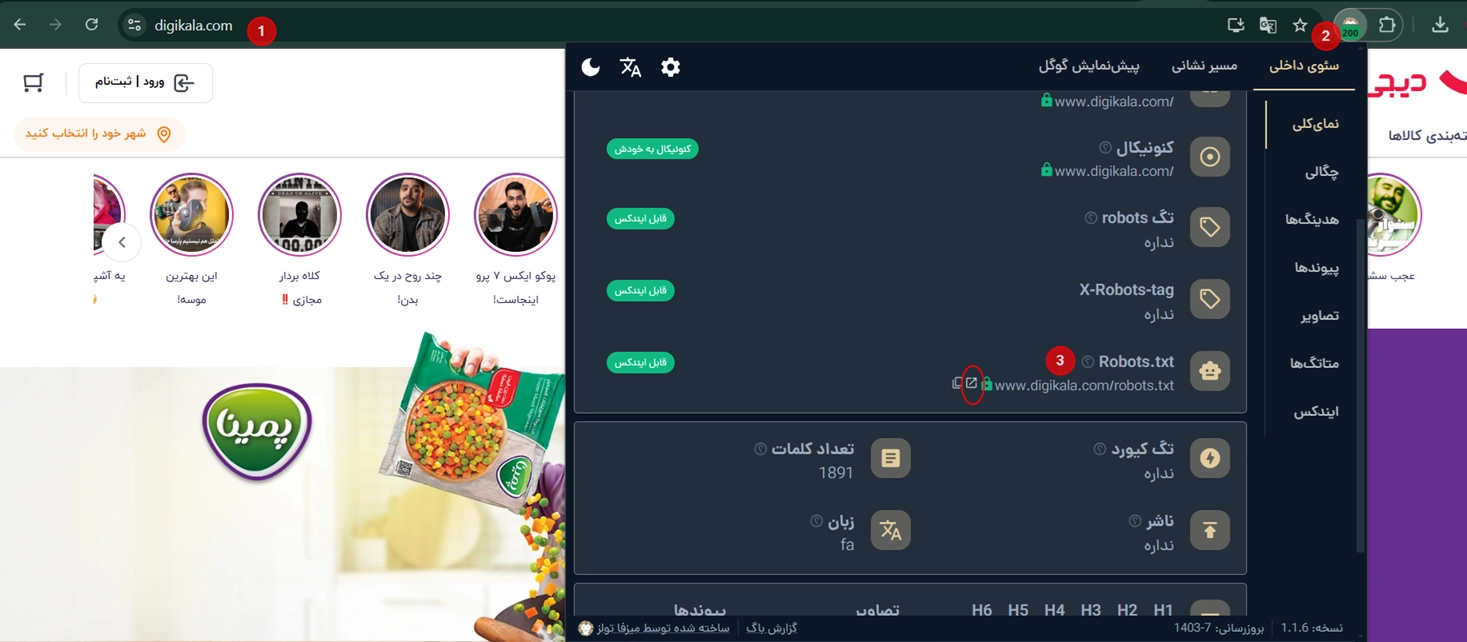
چجوری میتونیم فایل robots.txt رو ببینیم؟ فرض کنیم سایت ما mizfa.tools هست، پس آدرس فایل ربات به صورت زیر میشه:
mizfa.tools/robots.txtحالا بعد از اینکه robots.txt رو به انتهای آدرس سایت اضافه کردین، با یه صفحه مشابه عکس پایین مواجه میشید👇. البته این فقط یه نمونهست و همه سایتها ممکنه فایلشون متفاوت باشه.
User-agent: *
Disallow: /my-divar/*
Disallow: /manage/*
Disallow: /new
Disallow: /s/*/*?*q=*
Disallow: /adminbotیه راه سادهتر برای برای دیدن فایل robots.txt هر سایتی، کافیه افزونه گوگل کروم میزفا تولز رو نصب کنین. بعد از نصب، سایت مورد نظر رو جستجو کنید، مثلاً دیجیکالا، و از قسمت robots.txt که در افزونه هست استفاده کنید تا فایل robots.txt سایت رو ببینین. به راحتی با این روش میتونین فایل رو مشاهده کنین.
فایل robots.txt مثل یک تابلو راهنمایی تو خیابونه که به رباتها میگه کجاها برن و کجاها نرن. رباتهای خوب (مثل موتور جستجو) این قوانین رو رعایت میکنن، ولی رباتهای بد (مثل اسپمها) ممکنه نادیده بگیرن. این فایل نمیتونه بهطور قطعی قوانین رو اجرا کنه، بلکه فقط دستورالعملهایی میده.
چرا فایل robots.txt مهمه؟
1. مسدود کردن صفحات غیرعمومی
گاهی اوقات، در سایت صفحاتی دارید که نمیخواید در نتایج جستجو نمایش داده بشن، مانند:
- نسخه آزمایشی (Staging) صفحات
- صفحات ورود (Login Pages)
- نتایج جستجوی داخلی
این صفحات باید در سایت وجود داشته باشن، اما نیازی نیست کاربران تصادفی از طریق جستجوی گوگل به اونها دسترسی داشته باشن. در این حالت، میتونید از robots.txt برای جلوگیری از خزیدن این صفحات توسط موتورهای جستجو استفاده کنید.
2. بهینهسازی بودجه خزش (Crawl Budget)
اگر متوجه شدید که بعضی از صفحات مهم سایت شما ایندکس نمیشن، ممکنه دچار مشکل بودجه خزش باشید. با استفاده از robots.txt میتونید صفحات غیرضروری رو مسدود کنید، تا بودجه خزش هدر نره.
3. جلوگیری از ایندکس شدن منابع خاص توسط موتورهای جستجو
با استفاده از متا تگ robots: noindex, nofollow میتونید از ایندکس شدن صفحات جلوگیری کنید. اما این روش برای فایلهای چندرسانهای مثل تصاویر و PDFها کارایی نداره. در چنین مواردی، بهتره از robots.txt استفاده کنید.
robots.txt چگونه کار میکنه؟
اول ببینیم موتورهای جستجو چجوری کار میکنن. موتورهای جستجو دو كار اصلی انجام میدن:
- خزيدن (Crawling): رباتهای گوگل وارد صفحات وب میشن و از طریق لینکها و URLهای جدید به صفحات دیگه راه پیدا میکنن. باتها محتواهایی مثل متن، عکسها و ویدیوها را مشاهده و تجزیه و تحلیل میکنن.
- ايندکس کردن (Indexing): گوگل اطلاعاتی رو که دیده آنالیز و تحلیل میکنه و برای نشون دادن تو نتایج گوگل ذخیرهسازی انجام میده.
- قبل از شروع خزيدن، رباتها اول فايل robots.txt را بررسی میكنن. اگر تو اين فايل اجازه دسترسی داده شده باشه، به خزيدن ادامه میدن، در غير اين صورت اون بخش از سايت رو ناديده می گيرن.
در بعضی ابزارهای سئو و خزندهها، مثل ابزار خزش میزفا تولز، گزینهای برای رعایت یا نادیده گرفتن robots.txt وجود داره. در قسمت تنظیمات ابزار خزش میزفا تولز مشخص شده “به فایل robots.txt توجه داشته باش” یعنی اینکه ابزار خزش باید به دستورالعملهای فایل robots.txt سایت توجه کنه.
✅ اگر این گزینه فعال باشد:
خزنده از قوانین و محدودیتهای تعیینشده در robots.txt پیروی میکنه.
✅ اگر غیرفعال باشد:
ابزار خزنده بدون توجه به robots.txt میتونه همهی صفحات سایت رو بررسی کنه، حتی اگر در فایل robots.txt محدود شده باشن.
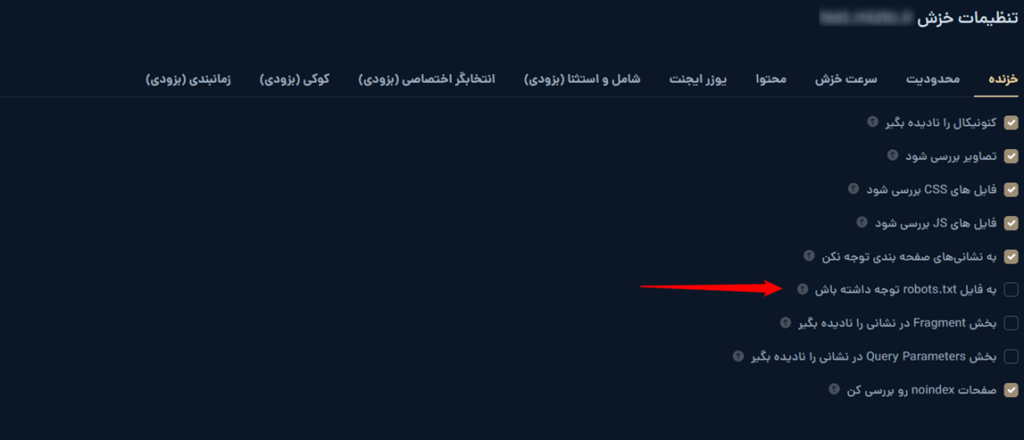
نکته: بهتره تیک گزینه «به فایل robots.txt توجه داشته باش» رو نزنید. برای ما فرقی نداره، ولی چون خودتون دارید سایتتون رو بررسی میکنید، نیازی به محدودیت اضافی نیست. این گزینه بیشتر برای مواقعی کاربرد داره که نمیخواید رباتهای دیگه بخشهایی از سایت رو ببینن، اما در میزفا تولز خودتون دادهها رو بررسی میکنید، پس نیازی به فعالسازی نیست.
چه دستوراتی در فایل robots.txt وجود داره؟
ممکنه براتون سوال پیش بیاد چجوری میشه با robots.txt اجازه دسترسی رو بست یا باز گذاشت؟
- User-agent: در این بخش رباتی که دستورات برای اون نوشته شده رو مشخص میکنیم.
- Allow: اجازه خزيدن به رباتها داده میشه.
- Disallow: از خزيدن رباتها جلوگيری میشه.
- Sitemap: از این دستور برای نشون دادن آدرس فایل نقشه سایت به رباتها استفاده میکنیم.
- Crawl-delay: دستوری که به رباتها میگه باید چند ثانیه قبل از درخواست بعدی صبر کنند تا از فشار زیاد روی سرور سایت جلوگیری بشه.
User-agent: *
allow: /
disallow: /search/userssitemap: https://mizfa.tools.com/sitemapindex.xmlحالا میخوام با یک مثال این دستورات رو براتون جا بندازم:
تصور کنید یه فروشگاه دارید، یه جای بزرگ و شلوغ که کلی قفسه، اتاق و بخش مختلف داره. مشتریها (همون رباتهای موتور جستجو) میان توی فروشگاه و میخوان همهجا رو ببینن، اما خب، شاید نخواید به همهجا دسترسی داشته باشن! مثلاً، انبار یا دفتر مدیریت رو که نباید بگردن، درسته؟ میتونیم چند تا قانون برای فروشگاهمون بذاریم.
🔹user agent: اول از همه، باید مشخص کنید این قوانین برای کدوم مشتری (ربات) هست. اگه بخوای یه قانون کلی برای همه بذاری، میگی:
User-agent:*یعنی هر کی میخواد بیاد، این قانون براش اعمال میشه. ولی اگه بخوای یه مشتری خاص، مثلاً فقط گوگل رو هدف بگیری، میگی:
User-agent:Googlebotیعنی فقط گوگل، این قانون برای توئه!
🔹 Disallow: اگه یه بخش خاصی از فروشگاه رو نمیخواید کسی ببینه، درش رو قفل میکنید! مثلاً:
Disallow: /admin یعنی آهای رباتا دفتر مدیریت ممنوعه
Disallow: /private یعنی اینجا اطلاعات شخصیه، نباید ببینید
🔹 Allow: حالا فرض کن گفتی کسی نباید بره توی انبار (Disallow)، ولی یه قفسه از انبار رو دوست داری نشون بدی، مثلاً محصولات جدید. میتونی یه استثنا قائل بشی:
Disallow: /storage
Allow: /storage/new-products.htmlاین یعنی کلاً به انبار نیاید، ولی این بخش جدید مشکلی نداره، ببینید!
🔹 Sitemap: خب، حالا که فروشگاه داری، شاید بد نباشه یه نقشه راهنما هم به مشتریا بدی، نه؟ توی سایت هم همینطوره، با این دستور به موتورهای جستجو میگی که نقشه کلی سایت رو از کجا پیدا کنن:
Sitemap: https://mizfa.tools.com/sitemap.xmlهمچنین میتونید سایت مپ رو از طریق سرچ کنسول بسازید و ثبت کنید.
مطالعه بیشتر: ساخت سایت مپ در سرچ کنسول
🔹 Crawl-delay: بعضی وقتا فروشگاه شلوغ میشه و نمیخواید مشتریها یهویی حمله کنن و همهجا رو پر کنن. اینجا میتونی بگی که هر چند ثانیه یه بار بیان، نه پشت سر هم! مثلاً:
Crawl-delay:1یعنی هر ۱۰ ثانیه یه بار بیا، عجله نکن! (البته گوگل از این پشتیبانی نمیکنه)
نکته: یک نکته مهم اینه که همه زیر دامنهها باید فایل robots.txt خود را داشته باشند. مثلا اگر سایت شما mizfa.com باشه و مقالات شما mizfa.tools.com باشه، باید برای هر دو یک فایل robots.txt جداگانه ایجاد کنید.
نمونه مناسب فایل robots.txt برای وردپرس
User-agent: *
Disallow:
Sitemap: https://mizfa.tools/sitemap_index.xmlنکتهی مهم درباره سابدامینها و فایل robots.txt 🚨
هر سابدامین فایل robots.txt خودش رو داره!
مثلا اگه تصاویر سایت روی یه سابدامین دیگه باشن و فایل robots.txt اون رو چک نکرده باشین و Disallow باشه، گوگل دیگه تصاویر رو کراول نمیکنه و شما ورودی تصاویر از گوگل نمیگیرین.
صحت فایل robots.txt رو با چی تست کنیم؟
بعد از اینکه فایل robots.txt رو ساختین یا تغییر دادین، خیلی مهمه مطمئن بشین که درست کار میکنه و گوگل هم میتونه به درستی صفحات مجاز رو کراول کنه.
برای این کار میتونین از ابزار زیر استفاده کنین:
https://technicalseo.com/tools/robots-txt
با این ابزار مطمئن میشین فایل شما بدون مشکل کار میکنه.
فرق فایل robots.txt با Noindex چیه؟
خیلیها فکر میکنن که وقتی یه صفحه یا دایرکتوری رو تو robots.txt مسدود میکنن یعنی گوگل ایندکسش نمیکنه. اما قضیه اینطوری نیست!
- Noindex: وقتی این تگ رو روی یک صفحه میذارین، گوگل مطمئن میشه که اون صفحه از ایندکس خودش خارج بشه. حتی اگر صفحه کراول هم شده باشه، با Noindex دیگه تو نتایج نشون داده نمیشه.
- Disallow در robots.txt: وقتی این دستور رو میذارین، فقط به گوگل میگین که این بخش رو کراول نکنه. ولی توجه داشته باشین: کراول نکردن به معنای ایندکس نکردن نیست!
- مثال: اگر گوگل قبلا URL شما رو پیدا کرده باشه و ایندکس شده باشه، بعدش شما دایرکتوری A رو با
Disallowبلاک کنین، گوگل دیگه نمیتونه کراولش کنه اما ایندکس قبلی همچنان باقی میمونه و ممکنه تو نتایج نمایش داده بشه.
- مثال: اگر گوگل قبلا URL شما رو پیدا کرده باشه و ایندکس شده باشه، بعدش شما دایرکتوری A رو با
- Allow در robots.txt: برعکس Disallow، اجازه میده گوگل اون صفحات یا دایرکتوریها رو کراول کنه.
💡 نکتهی مهم: گاهی وقتی کراول یه صفحه رو با robots.txt میبندین، گوگل عنوان و توضیحات صفحه رو از نتایجش به شکل DNS نمایش میده یا اطلاعات ناقص نشون میده، چون خودش نتونسته محتوا رو بخونه.
پس خلاصهش اینه:Noindex = صفحه رو ایندکس نکن.Disallow = صفحه رو کراول نکن، ولی ایندکس ممکنه بشه.
5 روش حذف صفحات از نتایج گوگل
۱. متا تگ Noindex
استفاده از متا تگ noindex بهترین روش برای جلوگیری از ایندکس شدن صفحه در نتایج جستجوست و به موتورهای جستجو میگه که صفحه نباید ایندکس بشه.

۲. خطای 410 و 404
اگر قصد دارید صفحهای را کاملا حذف کنید و دیگه هیچ ارزشی برای شما نداره، میتونید از خطای ۴۱۰ یا ۴۰۴ استفاده کنید.
- خطای ۴۱۰ برای حذف دائمی صفحه از نتایج جستجو مناسبتره چون سریعتر عمل میکنه.
- خطای ۴۰۴ به معنای “صفحه پیدا نشد” است و برای حذف دائمی مناسب نیست، چون ممکنه گوگل اون رو بهعنوان یک مشکل موقت در نظر بگیره.
۳. فایل Robots.txt
این فایل به موتورهای جستجو دستور میده که از کرال کردن برخی صفحات خودداری کنند، اما گاهی نتیجه دلخواه رو نمیده.
۴. خطای 403
در بعضی سایتهای اختصاصی، برای صفحاتی که نباید در نتایج جستجو بیان، از خطای 403 استفاده میشه. این خطا نشان میده که دسترسی به صفحه ممنوعه و هیچکس نمیتونه اون رو مشاهده کنه. خطا ۴۰۳ بیشتر برای مسائل امنیتی استفاده میشه.
۵. ابزار Removals سرچ کنسول
ابزار Removals سرچ کنسول برای حذف موقت صفحات از نتایج جستجو به کار میره و روش دائمی نیست، بنابراین برای حذف قطعی از روشهای بالا استفاده کنید.
فایلهای JavaScript و CSS رو از طریق robots.txt مسدود نکنید
💡 حتما دقت کنین که فایل robots.txt شما:
- اجازه بده CSS، JS و Images کراول بشن (
Allow)
اگر به رباتهای گوگل اجازه ندید فایلهای JavaScript و CSS رو کرال کنن باعث میشه موتورهای جستجو نتونن ساختار و محتوای سایت شما را به درستی درک کنن، که درنهایت میتونه به رتبهبندی شما آسیب بزنه.
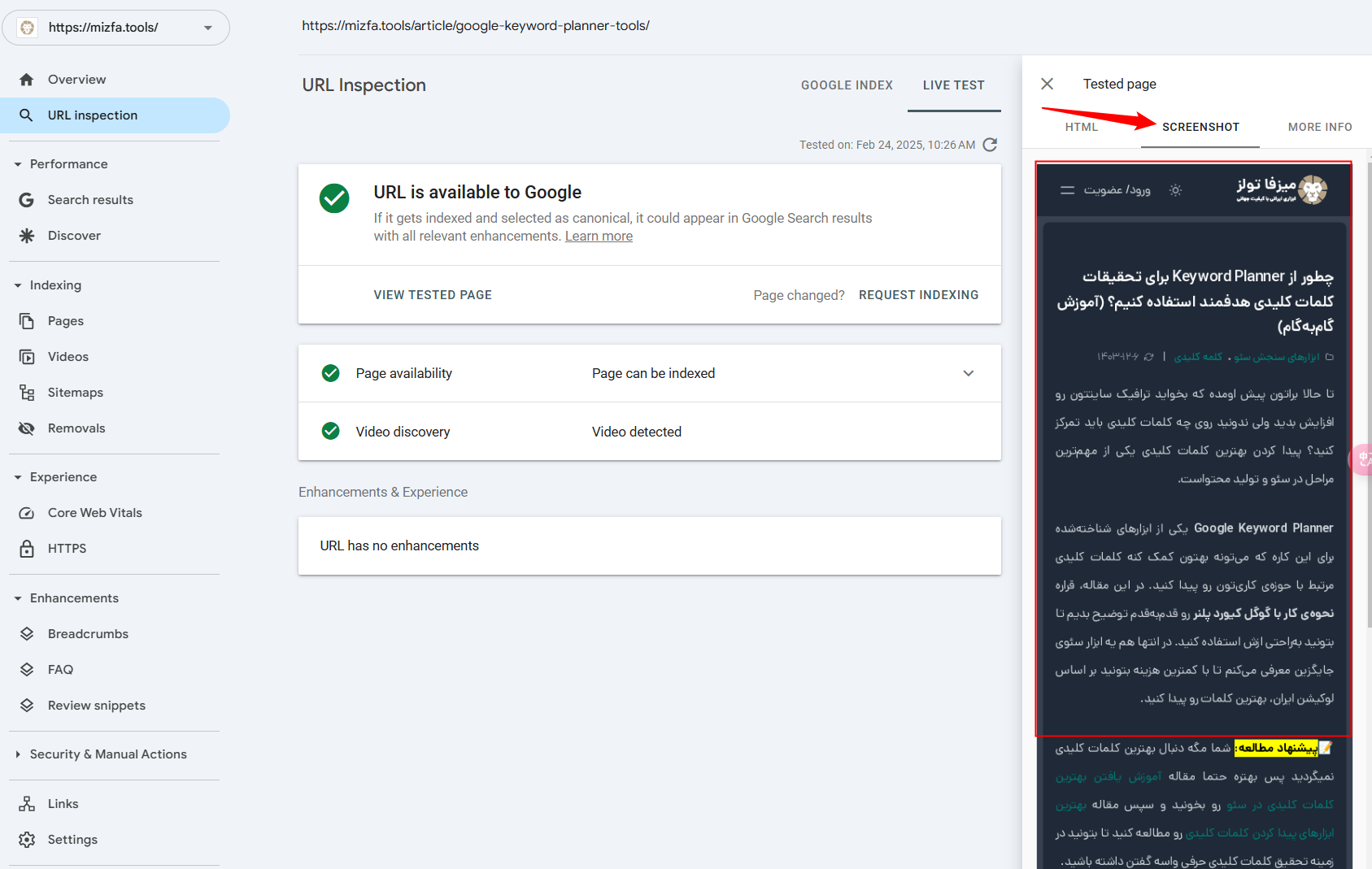
چطور بفهمیم ربات گوگل سایت ما رو چطور میبینه؟
برای بررسی اینکه رباتها سایت شما رو چطور میبینن، مراحل زیر رو دنبال کنین:
- وارد سرچ کنسول بشید.
- از قسمت URL Inspection سرچ کنسول آدرس صفحهای که میخواید بررسی کنید رو وارد کنین.
- بعد از وارد کردن آدرس، گزینهای به اسم Test Live Url در سرچ کنسول ظاهر میشه. روی اون کلیک کنین.
- چند ثانیه صبر کنین تا تست انجام بشه.
- بعد از انجام تست، از بخش Screenshot میتونین ببینید که رباتهای گوگل صفحه شما رو چطور میبینن.
اگر اینجا صفحه بهم ریخته یا درست نمایش داده نشد، بهتره دلیلش رو پیدا کنین و اصلاحش کنین.
AI Crawlers رو بلاک نکنید
خیلیها فکر میکنن ابزارهایی مثل ChatGPT یا دیگر AIها رو میتونن بلاک کنن تا محتوای سایتشون رو نخوان. اما این کار یه سری اثرات مهم داره:
- وقتی این ابزارها محتوای شما رو میخونن و تحلیل میکنن، احتمال منشن شدن سایت شما در جوابها و نتایج AI بالا میره.
- اگر صفحاتتون رو بلاک کنین (مثلا با Disallow)، دیگه این محتوا در دسترس AI نیست و ممکنه وقتی یه کاربر سوال میپرسه، سایت شما رو بهش معرفی نکنه.
- از طرف دیگه، این ابزارها دارن موتورهای جستجوی خودشو راهاندازی میکنن و کراولرهاشون رو میفرستن؛ این کراولرها نباید بلاک بشن، چون باعث میشه محتوای شما تو این سرویسها دیده نشه.
💡 مثال عملی:
فرض کن کاربر میپرسه «بهترین گوشیهای ۱۴۰۴ کدامند؟»
- اگر شما کراولر ChatGPT رو بلاک نکرده باشین، محتوا شما ممکنه تو جوابها یا منابع ذکر بشه.
- اما اگر بلاک کرده باشین، حتی با وجود اینکه محتوا در سایت شما هست، از منشن شدن تو پاسخها جا میمونین.
در نهایت چرا به robots.txt نیاز داریم؟
✅ جلوگیری از خزیدن محتوای تکراری
✅ محدود کردن دسترسی به بخشهای خصوصی
✅ مشخص کردن نقشه سایت (site map) برای موتورهای جستجو
✅ تنظیم سرعت خزیدن (Delay Crawl) برای کاهش فشار روی سرور
و در آخر اینکه نام فایل حساس به حروف بزرگ و کوچکه. حتما از robots.txt با حرف کوچک استفاده کنید مثلا نباید بنویسید Robot.txt یا robot.TXT و…. . فایل robots.txt رو در ریشه (Root) سایت خود قرار بدید تا موتورهای جستجو بتونن فایل رو پیدا کنن.
فایل robots.txt دقیقا چه نقشی در سئو سایت داره؟
افزایش سرعت بارگذاری صفحات
کنترل دسترسی رباتها به بخشهای مختلف سایت
بهبود طراحی گرافیکی سایت
افزای�ش نرخ تبدیل کاربران